Hit Identification
We operate as your virtual structural biology and screening lab, integrating AI-driven virtual screening with high-throughput biophysical validation. Whether you are a seed-stage biotech with compute and chemistry assets but no protein infrastructure, or a pharma team pursuing membrane proteins and PPI targets, we de-risk your early discovery pipeline under one roof.
Creative Biostructure at a Glance
Why Partner With Us
Most discovery programs fail not because the science is wrong — but because the infrastructure is fragmented. Virtual biotechs burn runway coordinating vendors. Pharma teams lose months to handoff delays between a computational CRO, a protein expression shop, and a crystallography facility. We built Creative Biostructure to eliminate that friction: one platform where AI-driven virtual screening and industrial-grade biophysical validation share the same project team, the same data system, and the same milestone clock.
Your CapEx is in compute and chemistry. Ours is in protein infrastructure.
| Stage | What We Deliver | What You Don't Need to Build |
|---|---|---|
| Gene-to-Protein | Codon optimization, multi-system expression screening, purification | Molecular biology lab |
| Structural Enablement | AI-assisted crystallization screening , Cryo-EM sample prep , NMR | Synchrotron beamline, EM facility |
| Hit Finding | Virtual screening → HTS/FBDD/HCS → biophysical validation | Automated liquid handling, SPR, ITC |
| Data Handoff | Co-crystal structure/EMDB map + SAR rationale + ADMET risk flags | — |
Production-Ready Deliverables: Every hit ships with computational docking models , binding free energy data , and structural coordinates — your chemists can enter optimization immediately, or our Hit-to-Lead team can advance the program.
- ✓ Milestone-based pricing aligned with your fundraising cycles
- ✓ No vendor coordination overhead — dry lab and wet lab under a single project manager
Membrane proteins. Large complexes. Nucleic acid-protein assemblies. PPIs.
"Undruggable" is our starting point.
Proven track record where others fail
GPCRs, ion channels, transporters, and nucleic acid-protein complexes — targets that crash standard CRO workflows.
Multi-modal pivot capability
When HTS yields low hit rates, we automatically deploy FBDD + Cryo-EM for structural insight; when biophysical validation is needed, SPR/ITC/BLI are on standby.
IP firewall & encrypted data infrastructure
Full audit trails, GLP-ready documentation, client retains 100% ownership of all data.
Core Service Modules
Service Module At-a-Glance
| Service | Core Capability | Structural + Computational Integration | Typical Timeline |
|---|---|---|---|
| Library Design | 10M+ physical compounds + AI-customized focused sets | SBVS/LBVS against AI-predicted or experimental structures | 2–4 weeks |
| HTS Assay Dev | FRET/TR-FRET/FP/AlphaScreen + cellular functional assays | MD simulation for buffer optimization; structure-guided reference compound selection | 3–6 weeks |
| HTS | 100K compounds/day automated screening | AI virtual pre-screening + high-throughput crystallography / Cryo-EM hit validation | 4–8 weeks |
| FBS | SPR/NMR/MS/TSA/ITC/BLI for mM–μM fragment detection | Hotspot analysis + fragment growing + co-crystal/Cryo-EM structural validation | 6–10 weeks |
| HCS | Multi-parameter phenotypic imaging in disease-relevant cells | Deep learning image analysis + transcriptomic matching for MoA deconvolution | 4–8 weeks |
MagHelix™ Library Design and Preparation
Physical Libraries Meet AI-Driven Virtual Design

Key Features of Our Library Design Services:
- 10M+ Diverse Physical Compound Collections — Spanning natural products, FDA-approved drugs, target-focused subsets (kinases, GPCRs, proteases, ion channels), and drug-like fragment libraries. All compounds are purity-verified by LC-MS and NMR.
- AI-Customized Focused Library Design — Our computational team employs structure-based virtual screening, pharmacophore modeling, and ADME/T prediction to tailor "made-to-order" screening sets based on your target's binding pocket topology.
- Gene-to-Structure Integration — Libraries can be designed against AI-predicted or experimentally determined structures, ensuring the chemical space explored is structurally relevant from day one.
Explore the Power of Smart Library Design:
Whether you have a well-characterized crystal structure or a homology model, we bridge computational library design with physical compound logistics. For seed-stage biotechs without existing collections, our AI-focused libraries maximize hit probability while minimizing screening costs. For pharma teams, we supplement internal libraries with computationally enriched external chemical matter, and every compound is tracked from virtual selection to plate delivery under encrypted data protocols.
Explore Library Design →MagHelix™ HTS Assay Development
Biochemical & Cellular Assays Optimized by Molecular Simulation

Key Features of Our HTS Assay Development Services:
- Multi-Modal Detection Platforms — FRET, TR-FRET, FP, AlphaScreen, luminescence, and cellular functional readouts for enzymes, receptors, PPIs, and ion channels. Assays are validated for robustness (Z' > 0.5), reliability, and cost-efficiency.
- In Silico Condition Optimization — Molecular dynamics simulations predict target conformational stability and active-state populations under varying buffer, pH, and cofactor conditions, shortening empirical optimization cycles.
- Structure-Guided Assay Design — For projects with available co-crystal structures or Cryo-EM maps, we use binding pocket analysis to select detection formats and reference compounds that are structurally validated.
What We Offer:
Traditional assay development relies on months of empirical buffer screening. Our integrated approach uses microsecond-level MD and binding free energy calculations to identify optimal protein constructs, buffer compositions, and detection formats before the first plate is run. We deliver assay validation reports with full specifications, SOPs, and QC statistics—ready for immediate transition to high-throughput screening.
Explore HTS Assay Development →High-Throughput Screening (HTS)
Computation-First Virtual Funnel + Biophysical Validation

Key Features of Our HTS Services:
- Automated High-Throughput Execution — 100,000+ compounds/day via Tecan Fluent / Hamilton Vantage liquid handling, multimode plate readers, and automated compound management. Full barcode tracking and sample integrity monitoring.
- AI-Driven Pre-Screening — AI-enhanced virtual screening at the 10^8-compound scale using molecular docking, pharmacophore matching, and ML scoring reduces physical screening load by >90% while improving hit rates 3–5 fold.
- High-Throughput Structural Validation — Our integrated high-throughput crystallography and Cryo-EM capabilities enable rapid determination of multiple target-ligand complex structures, confirming binding modes at atomic resolution.
Explore the Power of Smart HTS:
For virtual biotechs, Smart HTS means you only pay for physical testing on compounds that have already survived a billion-molecule computational gauntlet. For pharma teams, it means your proprietary collections are deployed with maximum efficiency. When primary screening completes, hits move directly into biophysical confirmation (SPR/ITC) and structural studies—no vendor handoffs, no lost momentum.
Explore HTS Services →Fragment-Based Screening (FBS)
Weak-Affinity Biophysical Detection + Computational Fragment Growing
Key Features of Our FBS Services:
- Sensitive Biophysical Platforms — SPR, NMR, TSA, ITC, BLI, and MS specifically tuned to detect weak fragment binding (mM–μM) for low molecular weight compounds (150–300 Da).
- Computational Hotspot & Growing Analysis — Binding pocket analysis identifies key interaction regions to guide rational fragment library selection. Molecular docking and MD simulations predict optimal fragment-growing vectors to transform weak binders into high-affinity leads.
- One-Stop Gene-to-Structure Support — We provide target protein production, purification, and co-crystal soaking / Cryo-EM validation under a single project structure.
What We Offer:
FBS is our preferred entry point for "undruggable" targets—membrane proteins with shallow pockets, PPI flat interfaces, and nucleic acid-protein complexes where traditional HTS libraries fail. Our MagHelix™ FBDD Platform integrates CADD, structural biology, and biophysics under one roof. Fragment hits are validated structurally from day one, giving your medicinal chemistry team atomic-resolution guidance for optimization.
Explore FBS Services →High-Content Screening (HCS)
Phenotypic Cell Models Analyzed by Deep Learning
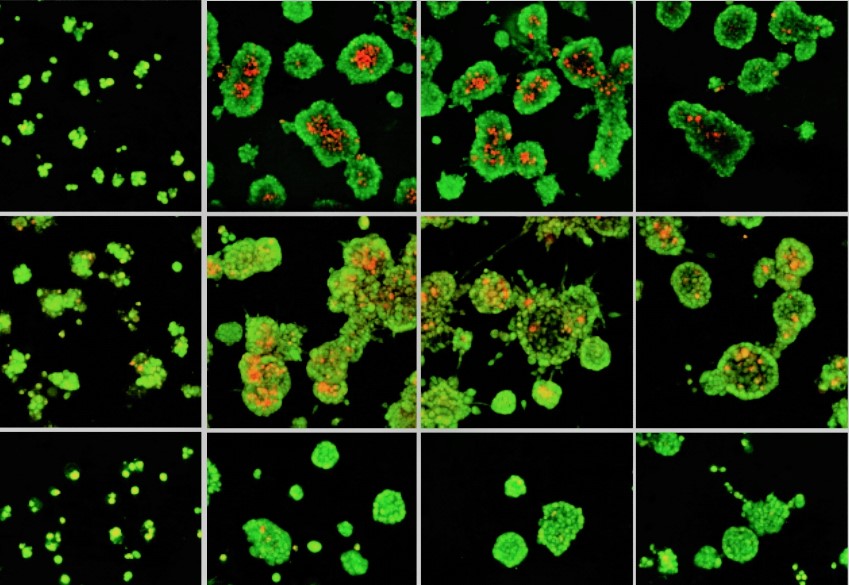
Key Features of Our HCS Services:
- Multi-Parameter Phenotypic Imaging — Automated high-resolution systems simultaneously monitor cell morphology, signaling pathway activation, organelle dynamics, and subcellular rearrangements—critical for diseases with complex or unclear mechanisms.
- AI-Driven Image Analysis — Deep learning algorithms perform automated feature extraction and unsupervised clustering, identifying compounds with unique mechanisms of action (MoA) that single-parameter biochemical screens miss.
- Physiologically Relevant Disease Models — Screening in primary cells, iPSC-derived models, and engineered reporter lines captures phenotypes closer to natural physiological states, rapidly excluding cytotoxic or membrane-impermeable compounds.
Explore the Power of AI-Enhanced Phenotypic Screening:
For targets where the biology is not fully validated, HCS provides an unbiased, systems-level entry point. Our computational pipeline connects cellular phenotypes to molecular hypotheses through in silico transcriptomic matching and pathway analysis. When combined with our zebrafish in vivo platform, HCS hits can be triaged for efficacy and toxicity in whole-organism models within weeks.
Explore HCS Services →Technology Platform
Integrated Discovery Infrastructure: Dry Lab + Wet Lab, Zero Handoffs
Our integrated drug discovery platform spans computation and experiment — enabling end-to-end Hit Identification without the delays, IP leaks, and miscommunication that come from coordinating multiple vendors. For teams pursuing challenging targets or working against tight fundraising milestones, this vertical integration is the operational difference between a strategic R&D partner and a simple service provider.
Computational Platform — Dry Lab
Powered by our MagHelix™ CADD Platform and MagHelix™ AIDD Platform
| Capability | Details |
|---|---|
| AI/ML Discovery Engine | GNN and Transformer architectures for affinity prediction; VAE/GAN-based generative molecular design; proprietary ML scoring pipelines retrained with each closed-loop project |
| Structure-Based Docking | Glide, AutoDock-GPU, and customized scoring pipelines; induced-fit and covalent docking enabled |
| Ligand-Based Methods | Pharmacophore mapping, shape-based screening, and QSAR models for targets without crystal structures |
| ADMET Prediction | Deep learning ADMET panel: Fsp3, LogP, hERG, CYP450, Papp, BBB permeability — filtering liabilities before synthesis |
| Molecular Dynamics | GROMACS / AMBER microsecond all-atom simulations; enhanced sampling (membrane protein-lipid systems, metadynamics, REST2) |
| Virtual Library Access | >10 billion accessible compounds (Enamine REAL, WuXi, proprietary fragments) + AI-customized focused libraries |
| Structure Prediction | AlphaFold2 / RoseTTAFold for apo and complex modeling; homology modeling for novel targets |
Computational Edge: For seed-stage biotechs, this means you can initiate virtual screening campaigns on billion-compound libraries while your protein is still in expression — no waiting for purified material to start hit discovery.

CADD Multi-Screen Workstation
AI-Assisted Structural Biology Lab Interface

HPC & AI Server Infrastructure
Biophysical Validation Platform — Wet Lab
Powered by our MagHelix™ Structural Biology and SBDD Platform
| Capability | Details |
|---|---|
| Surface Plasmon Resonance (SPR) | Biacore 8K+ / T200; full kinetics (kon/koff), affinity (KD), and thermodynamic characterization |
| Nuclear Magnetic Resonance (NMR) | Bruker 600MHz+; WaterLOGSY, STD-NMR, HSQC for fragment hit confirmation |
| Cryo-Electron Microscopy | Thermo Fisher Glacios / Krios G4; high-resolution structure determination for large complexes and membrane proteins |
| Isothermal Titration Calorimetry | MicroCal PEAQ-ITC; full thermodynamic binding characterization (ΔG, ΔH, ΔS, stoichiometry) |
| Thermal Stability Assays | Prometheus NT.48 DSF / DSC; rapid hit confirmation and buffer optimization |
| HTS Automation | Tecan Fluent / Hamilton Vantage liquid handling; 384- and 1536-well compatible; 100,000+ wells/day |
| High-Content Imaging | Multi-channel automated fluorescence microscopy with AI-driven image analysis |
| Biochemical Assay Platforms | FRET, TR-FRET, FP, AlphaScreen; homogeneous and cell-based detection formats |
Wet Lab Edge: For difficult targets, the ability to pivot from HTS to FBDD to Cryo-EM without changing project teams or renegotiating contracts protects your timeline and budget.

Biacore 8K+

Thermo Fisher Krios G4

Tecan Fluent
Platform specifications are subject to continuous upgrade. Contact our team for instrument availability and project-specific capability assessment.
Closed-Loop Discovery Engine
When Prediction Meets Validation
Traditional CROs operate on a handoff model. Our platform feeds every experimental result back into the AI models — so each campaign improves the next.
AI Virtual Pre-screening
10^8-scale docking and ADMET filtering reduces physical screening load by >90%.
Feeds into Wet-lab
Biophysical Confirmation
SPR/ITC binding kinetics refine ML scoring models for the next virtual campaign.
Feeds into Scoring
Structural Validation
Cryo-EM and co-crystal structures update induced-fit docking protocols.
Feeds into Models
Phenotypic & ADMET Feedback
HCS toxicity signals and cellular phenotypes train multi-parameter optimization.
Feeds back into AI
Industrial Value:
For biotechs
Your Phase 0 structural data becomes training data for Phase 1 targets. You don't just buy a service — you invest in a compounding learning partnership.
For pharma
Every computational prediction is linked to an experimental outcome with project ID, timestamp, and model version — fully audit-ready for regulatory submissions and internal portfolio reviews.
Project Management & Execution
Project Workflow
A standardized, milestone-driven execution system. From target review to validated hit delivery — managed by a single project team, tracked in real time.


01 Strategy
- In-depth target review, druggability assessment, and competitive landscape analysis
- Screening modality selection: HTS, FBDD, or HCS
Deliverable: Project proposal with Gantt-chart milestones, budget, and risk matrix
02 In Silico
- Target structure modeling / optimization (X-ray / Cryo-EM / AI prediction)
- Large-scale virtual screening + molecular docking at 10^8-compound scale
- Multi-parameter scoring and candidate ranking
Deliverable: Virtual screening report + Top 500 compound shortlist
03 Wet lab
- Biochemical / cellular assay development and validation (Z' > 0.5)
- HTS / FBDD / HCS execution
- Real-time data monitoring with positive/negative controls
Deliverable: Raw screening data + primary hit list
04 Validation
- Dose-response curves (IC50/EC50) and selectivity assessment
- Biophysical validation: SPR, ITC, TSA
- Structural biology: co-crystal structures / Cryo-EM / NMR
Deliverable: Validated hit report + structural data
05 Deliverables
- Complete screening data + Z' statistics and QC summaries
- Preliminary SAR analysis and clustering
- Computational docking models + binding mode predictions
- ADMET risk flags and follow-up optimization recommendations
- Hit-to-Lead transition plan
Deliverable: Final technical report + electronic data package
Sample Requirements
| Sample Type | Specification |
|---|---|
| Target Protein | Purity ≥90%, concentration ≥5 mg/mL, quantity ≥10 mg total; stability data (DSF Tm curve) strongly recommended |
| Reference Compounds | Known inhibitors or agonists as positive controls (if available; not required for first-in-class targets) |
| Compound Libraries | 10 mM in DMSO; 96- or 384-well plate format; SDF structure files required; plate map provided |
Standard Deliverables
Upon project completion, clients receive comprehensive experimental reports including:
- Complete screening data with Z'-factor statistics
- Hit compound lists with IC50/EC50 curves
- Preliminary structure-activity relationship (SAR) analysis
- Computational docking models with binding mode predictions
- Follow-up optimization recommendations with project retrospectives
Frequently Asked Questions
Case Study
Cryo-EM of CDXX Receptor–Antibody Complex
Goal: Resolve the 3D architecture of a membrane receptor–antibody complex to enable epitope mapping and structure-guided ligand design.
Key Data:
- Resolution: 3.05 Å (Titan Krios G3i, 300 kV)
- Particles: 605,141 processed → 254,737 refined after 3D classification
- Architecture: Two CDXX proteins + two antibodies in closed-state circular assembly
- Deliverable: Atomic model with mapped epitope (residues 205–301) ready for docking and fragment soaking
Why it matters: Membrane proteins and large complexes are where standard CRO workflows fail. This validates our end-to-end pipeline — mammalian expression, complex reconstitution, and single-particle analysis — under one project team. For big pharma outsourcing groups, it means a single accountability chain and audit-ready structural data. For biotechs, it means accessing Krios-class Cryo-EM infrastructure without the CapEx.
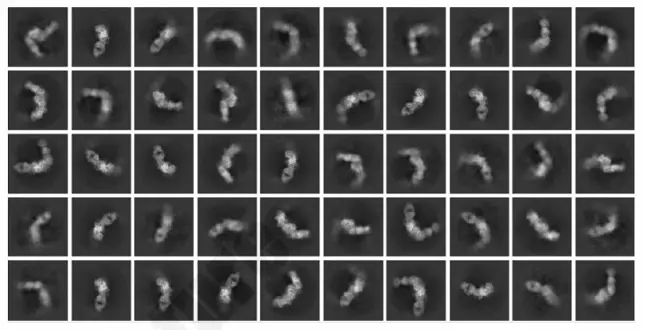
Figure 1. 2D class averages showing distinct secondary structure features and particle homogeneity.
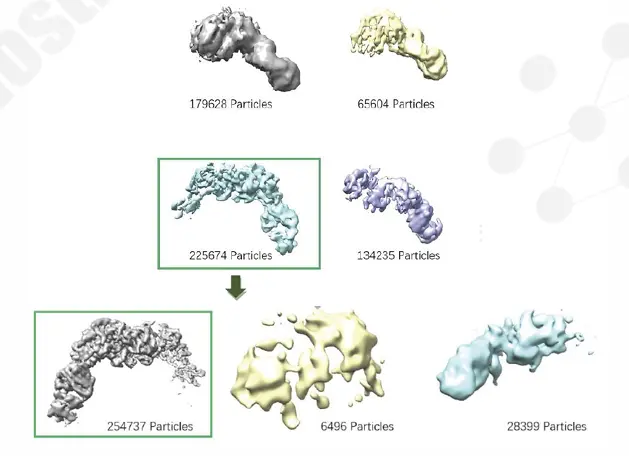
Figure 2. 3D classification from 605,141 particles to the final 254,737-particle class (green box).
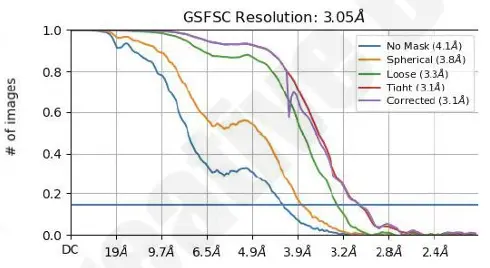
Figure 3. GSFSC curves confirming 3.05 Å resolution and angular distribution validating full orientation coverage.
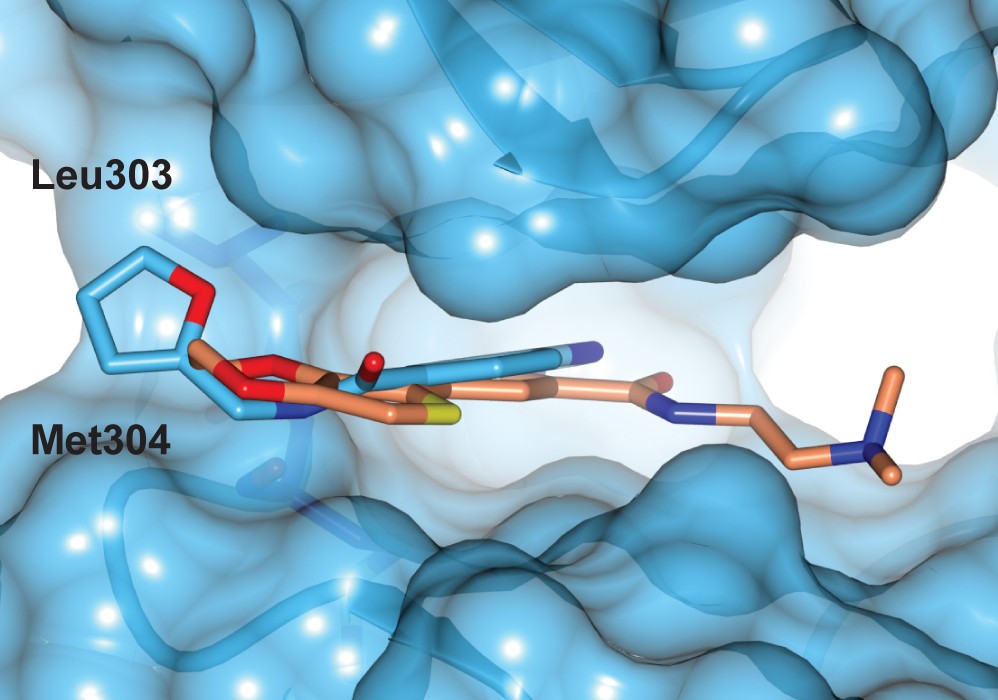
Structure-Based Virtual Screening for IQGAP1–Cdc42 PPI
Goal: Disrupt a protein–protein interaction (PPI) interface by identifying small-molecule binders via structure-based virtual screening and pocket-directed library design.
Key Data:
- Target: IQGAP1 GTPase-activating protein-related domain (GRD) in complex with Cdc42
- Structural basis: Homology model built from PDB 1WQ1, 3fay, and 1AN0
- Screening funnel: 1,000 top-scoring compounds by binding energy → cluster analysis → visual inspection for dual-pocket occupancy (A + B)
- Hit output: Prioritized compounds with docking scores, 3D binding modes, and 2D interaction maps (e.g., rank 5, score –7.98)
Why it matters: PPI targets are widely considered "undruggable." This case demonstrates our ability to structurally enable a PPI interface through homology modeling and pocket mapping, then execute a focused virtual screen against it. For biotechs, it means accessing CADD-driven hit discovery for targets your internal team may have deprioritized due to lack of structural starting points. For pharma outsourcing teams, it proves we can tackle the hardest target classes with a computation-first, structure-rationalized approach.
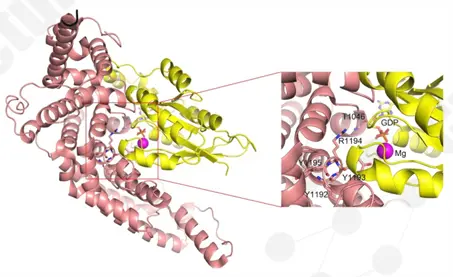
Figure 1. Binding site identification: GRD–Cdc42 complex model with conserved motif 1192YYR1194 at the PPI interface.
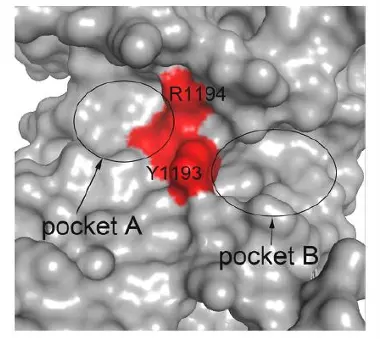
Figure 2. Pocket mapping: Two distinct binding pockets identified at the PPI interface for virtual screening.
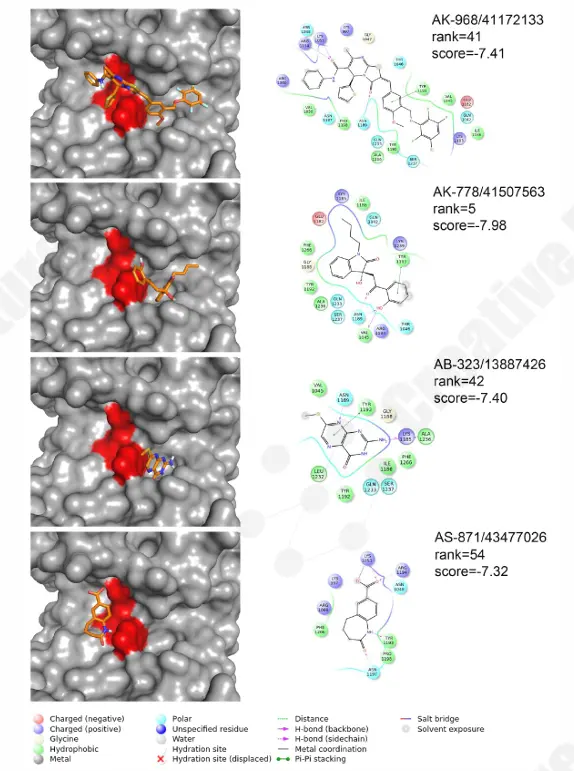
Figure 3. Hit prioritization: Representative binding modes and 2D interaction maps for top-ranked compounds.