Natural Product Research & Development
Natural products represent ideal starting points for first-in-class therapeutics, yet traditional R&D is paralyzed by analytical complexity, dereplication redundancy, and supply instability. Creative Biostructure operates as your virtual natural product lab, integrating AI-driven metabolomics mining, automated structural biology, and computational synthetic biology into a single execution system. Whether you are a seed-stage biotech extending your chemistry capabilities or a pharma team securing supply chains for rare scaffolds, we deliver end-to-end services—from crude extract to drug-ready compound—under predictable timelines and full documentation.
Creative Biostructure at a Glance
Why Partner With Us
Most natural product programs fail not because the biology is wrong—but because the infrastructure is fragmented. Virtual biotechs burn runway coordinating botanical suppliers, analytical CROs, and fermentation facilities. Pharma teams lose quarters to handoff delays between dereplication labs, structural biology facilities, and synthetic biology shops. We built Creative Biostructure to eliminate that friction: one platform where AI-driven mining, high-resolution structural elucidation, and engineered bio-production share the same project team, the same data system, and the same milestone clock.
Your CapEx is in compute and medicinal chemistry. Ours is in natural product infrastructure.
| Stage | What We Deliver | What You Don't Need to Build |
|---|---|---|
| Crude Extract to Pure Compound | AI dereplication + bioassay-guided fractionation + prep-HPLC/SFC purification | Natural product isolation lab and prep-chromatography farm |
| Structural Elucidation | AI-assisted NMR/XRD + absolute configuration determination | 600/800 MHz high-field NMR facility and crystallography suite |
| Scalable Production | Computational metabolic engineering + engineered strain fermentation | Microbial fermentation suite and synthetic biology lab |
| Data Handoff | Structural report + computational bioactivity brief + ADMET risk flags + zebrafish toxicity data | — |
Production-Ready Deliverables: Every identified compound ships with HRMS spectra, multi-dimensional NMR assignments, AI-validated structural analysis, and computational docking models against your target—your medicinal chemists can enter SAR analysis immediately, or our Hit-to-Lead team can advance the program.
- ✓ Milestone-based pricing aligned with your fundraising cycles
- ✓ No vendor coordination overhead—dry lab and wet lab under a single project manager
PPI modulators. Allosteric inhibitors. Membrane-protein ligands. Nature solved the scaffold—but supply didn't.
Proven track record in supply-constrained scaffolds
Complex terpenes, alkaloids, and polyketides traditionally limited by ecological availability—now manufactured at gram-per-liter scale via engineered microbes.
Multi-modal pivot capability
When HTS libraries fail against difficult targets, we deploy genome mining to discover silent biosynthetic gene clusters (BGCs) encoding novel chemical matter; when extraction yields are insufficient, we pivot to heterologous pathway reconstruction without restarting the project clock.
IP firewall & encrypted data infrastructure
Full audit trails, GLP-ready documentation, client retains 100% ownership of all structural data, strain lineages, and engineered pathway IP.
Core Service Modules
Service Module At-a-Glance
| Service | Core Capability | Structural + Computational Integration | Typical Timeline |
|---|---|---|---|
| Natural Product Identification | High-throughput separation (HPLC/SFC), bioassay-guided fractionation, and precise structural confirmation (HRMS, 600/800 MHz NMR, XRD) for microbial, plant, animal, and functional food sources. | AI-Powered Dereplication: Deep learning models auto-match LC-HRMS/MS² and NMR data against global repositories, cutting dereplication time by up to 60%. In Silico Target Prediction: Computational docking and pharmacophore modeling prioritize fractions before isolation, enabling "activity-guided" efficient identification. |
4–8 weeks for known-class dereplication and QC; 8–12 weeks for full novel structure elucidation (including absolute configuration). |
| Natural Product Production & Extraction | Customized production from lab-scale extraction optimization to large-scale engineered strain (E. coli/yeast) heterologous expression, with tech-transfer packages. | Computational Metabolic Engineering: AI-driven enzyme engineering and molecular dynamics simulations optimize synthetic pathway thermodynamics; metabolic flux rebalancing algorithms predict yield bottlenecks to guide rate-limiting enzyme evolution. | 12–20 weeks for pathway reconstruction and strain optimization; 4–8 weeks for pilot scale-up (up to 5L; 50L+ tech transfer available). |
Natural Product Identification
AI-Guided Dereplication and Structure-Guided Elucidation

Key Features of Our Identification Services:
- AI-Powered Dereplication: Machine learning algorithms instantly cross-reference LC-HRMS/MS² and NMR spectra against global natural product databases, eliminating redundant rediscovery and focusing resources exclusively on novel, high-value scaffolds.
- In Silico Target Prediction: Before a single fraction is collected, virtual screening and pharmacophore mapping against your target protein prioritize extracts with highest probability of bioactivity.
- Automated Structural Elucidation: Integrates 600/800 MHz high-field NMR and X-ray diffraction with AI-assisted spectral deconvolution software, achieving atomic-level precise characterization—even for trace, complex stereochemical structures.
What We Offer:
For virtual biotechs, this means knowing which fractions contain real leads before you spend a dollar on scale-up isolation. For pharma teams, it means dereplication cycles compressed from months to weeks, with structural data packages ready for patent filing and regulatory submission from day one.
Explore Natural Product Identification →Natural Product Production & Extraction
Computational Pathway Design to Industrial Fermentation

Key Features of Our Production Services:
- Computational Metabolic Engineering: AI-driven enzyme engineering and MD simulations optimize synthetic pathway thermodynamics; flux balance analysis predicts yield bottlenecks before bench work begins.
- Heterologous Host Reconstruction: Customized pathway reconstruction in E. coli or yeast, transforming laboratory milligram samples into industrial fermentation scale.
- Tech-Transfer Ready Scale-Up: Standard 5L pilot fermentation with batch-to-batch QC; 50L+ CMO tech-transfer packages available for clinical manufacturing continuity.
What We Offer:
Traditional natural product supply chains depend on agricultural land use and seasonal collection. Our platform replaces that volatility with microbial cell factories—scalable, cost-controlled, and fully auditable. For biotechs, this means access to rare scaffolds without botanical sourcing risk. For pharma, it means COGS predictability and supply chain security for IND-enabling studies.
Explore Natural Product Production →
Technology Platform
Integrated Discovery Infrastructure: Dry Lab + Wet Lab, Zero Handoffs
Our platform spans AI-driven metabolomics, automated structural biology, and engineered bio-production—enabling end-to-end natural product R&D without the delays, IP leaks, and miscommunication that come from coordinating multiple vendors.
Computational Platform — Dry Lab
Powered by our MagHelix™ CADD Platform and MagHelix™ AIDD Platform
| Capability | Details |
|---|---|
| AI/ML Dereplication Engine | Deep learning spectral matching against 100K+ natural product structures; real-time LC-HRMS/MS² and NMR auto-annotation |
| Genome Mining & BGC Prediction | Homology modeling and co-evolutionary analysis to identify silent biosynthetic gene clusters encoding novel secondary metabolites |
| Metabolic Flux Modeling | Flux balance analysis (FBA) and kinetic modeling to predict pathway bottlenecks and guide enzyme engineering priorities |
| Structure-Based Docking | Glide, AutoDock-GPU; induced-fit and covalent docking for natural product target deconvolution |
| ADMET Prediction | Deep learning panel: Fsp3, LogP, hERG, CYP450, Papp, BBB permeability—filtering liabilities before isolation |
| Molecular Dynamics | GROMACS/AMBER microsecond all-atom simulations; enzyme-substrate complex stability and membrane protein-lipid system validation |

NVIDIA DGX A100

Dell PowerEdge XE8545
AI Dereplication & Virtual Screening
Biophysical & Production Platform — Wet Lab
Powered by our MagHelix™ Structural Biology and SBDD Platform
| Capability | Details |
|---|---|
| Prep-HPLC / SFC Farms | High-throughput preparative separation systems for complex matrix fractionation and purity validation |
| 600/800 MHz NMR + XRD | Bruker AVANCE NEO systems; AI-assisted spectral deconvolution for trace-component structural elucidation |
| Fermentation Suite | 5L standard bioreactors with fed-batch and continuous culture capability; 50L+ tech-transfer to CMO partners |
| High-Resolution MS | Q-TOF and Orbitrap systems for HRMS, LC-MS/MS, and MS-based metabolomics profiling |
| Synthetic Biology Lab | Heterologous pathway reconstruction, CRISPR-based host engineering, and directed evolution protein engineering |

Waters AutoPurification System

Bruker AVANCE NEO 600 MHz

Sartorius Biostat B-Plus 5L
Platform specifications are subject to continuous upgrade. Contact our team for instrument availability and project-specific capability assessment.
Closed-Loop Discovery Engine
When Prediction Meets Validation
Traditional natural product CROs operate on a handoff model. Our platform feeds every experimental result back into the AI models—so each campaign improves the next.
AI Dereplication & Virtual Pre-screening
LC-HRMS/MS² and NMR spectra are auto-matched against global databases in real time, eliminating known compounds before wet-lab fractionation begins.
→ Feeds into Wet-lab
Bioassay-Guided Fractionation
Activity data from cellular or biochemical assays train ML models to predict which fractions contain target-class scaffolds, refining AI prioritization algorithms.
→ Feeds into AI Models
Structural Validation (NMR/XRD)
AI-assisted spectral deconvolution and co-crystal structures update docking and pharmacophore protocols for subsequent target campaigns.
→ Feeds into Docking/Pharmacophore
ADMET & Bioactivity Feedback
Zebrafish toxicity and cellular phenotype signals train multi-parameter optimization functions, enabling early elimination of liability-laden scaffolds before scale-up.
→ Feeds back into AI
Industrial Value:
For Biotechs
Your Phase 0 natural product data becomes training data for your Phase 1 campaigns. You don't just buy a service—you invest in a compounding learning partnership.
For Pharma
Every computational prediction is linked to an experimental outcome with project ID, timestamp, and model version—fully audit-ready for regulatory submissions and internal portfolio reviews.
Standardized Workflow
Project Workflow
A standardized, milestone-driven execution system. From extract receipt to engineered strain delivery—managed by a single project team, tracked in real time.


01 Digital Discovery & AI Screening
- Bioinformatics-driven chemical space prediction and silent BGC mining
- Activity-guided fractionation combined with virtual screening to lock in high-value leads
Deliverable: Prioritized target molecule profile + dereplication report
02 Advanced Structural Characterization
- HRMS for molecular formula determination
- AI-assisted NMR deconvolution and X-ray / CD for absolute configuration
Deliverable: Atomic-level structural identity report
03 Intelligent Route Optimization
- Parallel Path A (natural extraction optimization) and Path B (in silico pathway design + heterologous host)
- Computational flux modeling and DBTL loop for strain optimization
Deliverable: Optimized extraction protocol OR engineered strain lineage + pathway docs
04 QC, Scale-up & Delivery
- Rigorous QC validation: purity ≥95%, potency, chiral purity, residual solvent
- GMP-aligned fermentation scale-up with batch-to-batch consistency
Deliverable: QC release package + scaled product batch + consistency records
05 Integrated Deliverables
- Complete structural report + computational bioactivity brief with ADMET data
- High-purity compounds (≥95%) / optimized strains with Hit-to-Lead transition plan
Deliverable: Final technical report + electronic data package
Sample Requirements
| Sample Type | Specification |
|---|---|
| Raw Materials | Dried plants, mycelium, or biological tissues (typically 500 g – 2 kg) |
| Crude Extracts | Minimum 50 mg, with solvent extraction history noted (e.g., EtOH, MeOH, EtOAc) |
| Data Input | Preliminary bioassay data or target protein structures welcome for targeted AI modeling |
Standard Deliverables
- Structural identity report: Including HRMS, multi-dimensional NMR spectra, and AI-validated structural analysis (with absolute configuration)
- Computational bioactivity brief: Molecular binding models with target proteins and activity prediction data
- Product & strain: High-purity target compounds (typically ≥95%) and optimized engineered strains (for production projects)
Our technical team responds within 24 hours. All inquiries protected under NDA.
Frequently Asked Questions
A: Standard timelines range from 14–18 weeks for identification-only projects, and 20–22 weeks for full identification-to-production programs. Well-characterized plant extracts with existing bioassay data can be accelerated to 10–14 weeks for dereplication and QC. Novel microbial genome-mining projects requiring BGC identification and heterologous expression typically fall on the longer end (22–26 weeks). We provide Gantt-chart milestones at initiation and bi-weekly progress updates.
A: Our deep learning algorithms auto-match LC-HRMS/MS² and NMR spectra against global natural product databases in Week 1–2, eliminating known compounds before costly preparative isolation begins. This typically reduces dereplication cycles by 60% and prevents wasted FTE hours on redundant scaffolds—critical for seed-stage biotechs managing burn rate.
A: Yes. We deliver structural files (SDF, PDB) and bioactivity briefs compatible with your internal molecular docking and SAR workflows. Natural product hits can be directly funneled into our Hit-to-Lead biophysical characterization or zebrafish efficacy/toxicity models without vendor switching.
A: For complex molecules with low natural abundance, microbial production often achieves 10–100× yield improvements (as demonstrated in the longifolene case), converting milligram-per-liter economics to gram-per-liter viability. Once the strain is fixed, marginal production cost scales with fermentation capacity rather than agricultural land use or seasonal collection labor—providing predictable COGS for clinical manufacturing planning.
A: All novel structures and engineered strains are covered by contractual exclusivity and NDAs. We provide full structural data packages (NMR, HRMS, XRD) suitable for patent filing. For genome-mining projects, we report BGC sequences and chemical structures with clear novelty assessments against public databases. You retain 100% ownership of all data, strains, and pathway IP.
A: We operate from milligram analytical scale to 5L pilot fermentation as standard, with tech-transfer packages to 50L+ CMO partners. Batch consistency is enforced through standardized strain banking (master/working cell banks), defined media protocols, and QC release criteria (purity, potency, enantiomeric excess) aligned with preclinical ADMET standards.
A: Yes. Deliverables include Certificate of Analysis (CoA), full spectroscopic data, strain lineage records, and impurity profiles formatted for regulatory review. We coordinate with our ADMET and safety pharmacology teams to ensure downstream IND package continuity.
A: We build computational contingency strategies into every production proposal. If initial pathway reconstruction underperforms, we pivot without restarting the project clock: flux rebalancing algorithms identify alternative enzyme orthologs; protein engineering MD simulations guide directed evolution; or we evaluate alternative heterologous hosts (yeast vs. E. coli vs. actinomycetes). These pivot options are pre-discussed during strategy design.
A: Yes. We offer fixed-scope natural product projects (FFS) with milestone-based payments—ideal for seed-stage biotechs managing burn rate. We also offer dedicated FTE teams for ongoing natural product pipeline programs—ideal for Series A/B companies or pharma groups building proprietary libraries. Hybrid models (FFS for identification, FTE for production expansion) are available.
A: We operate as your virtual natural product R&D lab. You bring the target hypothesis and crude extract (or source organism); we handle AI dereplication, structural elucidation, and—if needed—engineered strain construction and fermentation scale-up. All deliverables are formatted for immediate handoff to your internal medicinal chemistry team or our Hit-to-Lead group. You get the infrastructure of a fully equipped natural products institute without the CapEx.
Case Study
Case Study: Engineering Yeast Cell Factories for High-Yield Sesquiterpene Production: A 2025 Benchmark in Computational Bio-Manufacturing
Goal: Replace volatile botanical sourcing of longifolene—a high-value natural sesquiterpene traditionally dependent on pine resin extraction—with a scalable, cost-controlled microbial manufacturing platform suitable for clinical development supply chains.
Key Data:
- Strain: Saccharomyces cerevisiae engineered via computational Mevalonate (MVA) pathway reconstruction.
- Computational Strategy: Systemic metabolic engineering directed primary metabolism toward Farnesyl Pyrophosphate (FPP); in silico modeling identified ERG9 squalene synthase as a competing pathway bottleneck.
- Technical Execution: Enzyme fusion engineering (FPP synthase + longifolene synthase linked by optimized protein linkers) for proximity-based catalysis; pathway rebalancing via ERG9 down-regulation and precursor supplementation; iterative Design-Build-Test-Learn (DBTL) loop for strain refinement.
- Titer Improvement: 14.28 mg/L → 1.21 g/L in fed-batch fermentation—an >85× improvement reaching commercially viable concentrations.
Why it matters: For drug developers pursuing natural product leads, this peer-reviewed case demonstrates three critical procurement advantages that de-risk pipeline supply strategies:
- Supply Independence: Microbial production eliminates agricultural commodity pricing volatility, seasonal collection risk, and ecological sourcing limitations.
- IP Positioning: Engineered strains and optimized heterologous pathways are fully patentable—unlike extracted natural products—creating defensible exclusivity for development programs.
- Regulatory Continuity: Fermentation-derived compounds deliver batch-to-batch consistency and controlled impurity profiles that align with IND-enabling ADMET requirements, unlike botanical extracts with inherent compositional variability.
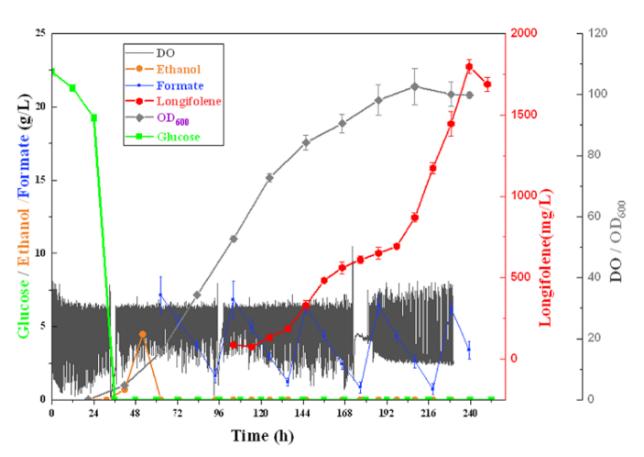
Figure 1. Scalable production of longifolene in a 5L fermentor system. (Xin Y, et al., 2025)
Reference:
- Xin Y, Du J, Zhang W, et al. Combining multiple metabolic strategies for efficient production of longifolene in Saccharomyces cerevisiae. Synth Syst Biotechnol. 2025 Nov 18;12:82-90.